如此编译
在学习计算机系统,通过汇编代码来理解计算机行为的过程中,笔者遇到了许多问题,也通过网上的许多教程理解了计算机的行为。一段汇编代码中往往有很多细节,但这些知识点总是分散的。笔者结合自己的学习过程,将学习笔记和网上的教程相结合,梳理学习脉络,以供自己和他人查看,希望大家都能有所收获,体会到计算机之美!
0xFF 更新
调用者保存和被调用者保存
todo
- 什么是调用者和被调用者保存
- 具体的实现
- 两种方法各有什么好处
- 在递归中的使用
0x00 编写一段代码
1 | #include <stdio.h> |
我们前往https://godbolt.org/中查看该代码的汇编形式
也可以gcc -S test.c生成test.s汇编代码文件
1 | .LC0: |
我们可以看到c语言代码被编译器编译成了寄存器与指令的各种操作,理解汇编层面的操作对理解计算机体系结构十分重要。
让我们一起通过详解这段代码,理解计算机操作中几个重要的概念。
0x01 寄存器
在x86-64架构中,有16个64位通用寄存器,分别是RAX、RBX、RCX、RDX、RSI、RDI、RBP、RSP、R8-R15。下面是每个寄存器的作用:
通用寄存器:
- RAX(accumulator,累加器):常用于存储函数返回值、算术运算、IO操作等。
- RBX(base,基址指针):通常被用作指针基址,存储数据地址。
- RCX(counter,计数器):通常用于循环计数器或IO端口的地址。
- RDX(data,数据寄存器):通常用于存储数据,如乘法、除法、移位操作等。
- RSI(source index,源索引寄存器):通常用于存储源数据地址。
- RDI(destination index,目的索引寄存器):通常用于存储目标数据地址。
- RBP(base pointer,基址指针):通常用于指向当前函数的基地址。
- RSP(stack pointer,栈指针):通常用于指向当前栈顶。
扩展通用寄存器:新增的通用寄存器,用于存储临时变量、指针、地址等。
- R8-R15
指令指针寄存器:
- RIP(instruction pointer,指令指针寄存器)
标志寄存器:
- RFLAGS(flags,标志寄存器)
浮点寄存器:
- XMM0-XMM15(浮点寄存器)
扩展浮点寄存器:
- YMM0-YMM15(扩展浮点寄存器)
向量寄存器:
- ZMM0-ZMM31(向量寄存器)
0x02 栈帧
程序的栈内存是一种特殊的内存区域,用于存储程序在运行过程中的局部变量、函数参数、返回地址和临时数据等。栈内存是由操作系统分配的一块连续的内存区域,大小通常固定,并且是在程序运行时动态分配的。
栈内存的管理是由操作系统的内核完成的。在程序执行过程中,每当函数被调用时,栈内存中会创建一个新的栈帧,该栈帧会包含函数的参数、返回地址和局部变量等数据。
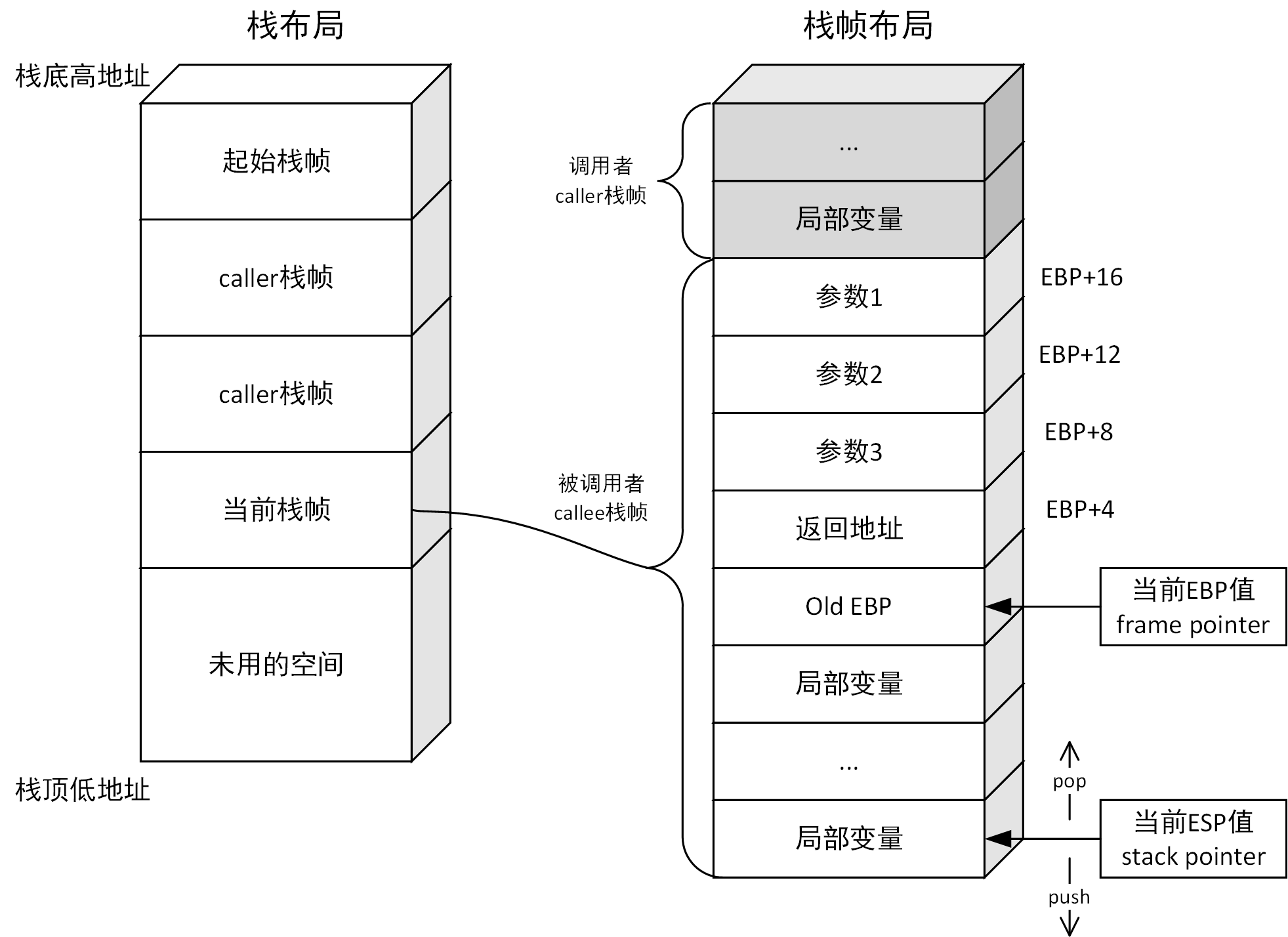
2.1 栈帧是如何运行的
- 当函数被调用时,调用指令会将函数的返回地址推入栈中,同时分配一块内存作为该函数的栈帧。
- 函数执行期间,该函数的局部变量、参数等数据都存储在该函数的栈帧中。栈帧指针指向栈顶,用于追踪栈帧的位置。
- 如果函数调用了其他函数,该函数的栈帧指针会被推入栈中,以便在该函数执行完毕后能够恢复之前的栈帧。
- 当函数执行完毕时,会将栈帧指针从栈中弹出,将控制权返回到上一个栈帧中。此时,栈帧被销毁,栈帧所占用的内存空间被释放。
- 如果程序没有更多的函数需要调用,程序将从栈中弹出最后一个栈帧,并将控制权返回到程序的入口点。
进入栈帧和退出栈帧时,栈帧指针的值会改变。当进入栈帧时,栈帧指针的值会指向分配给该函数的内存区域的顶部。当退出栈帧时,栈帧指针的值会指向上一个栈帧的顶部。由于栈的后进先出(LIFO)特性,每次进入和退出栈帧时,栈帧指针的值都会按照相反的顺序改变。
请注意栈中存储的是数据(包括局部变量和地址)而不是指令
2.2 栈帧的大小
栈帧的大小取决于函数使用的局部变量和参数的数量和类型。
栈帧的大小是在编译器编译过程中就已经确定的,编译器会根据函数的局部变量、参数、返回地址等信息来计算栈帧的大小。
在函数被调用时,操作系统会为该函数的栈帧分配一块连续的内存空间,并将该栈帧的大小与栈指针相加,指向新的栈帧起始位置。在函数执行过程中,栈指针会随着栈帧中的局部变量和其他数据的压栈和出栈而不断地变化。当函数执行完毕时,栈帧会被销毁,栈指针会回到上一个栈帧的位置。
0x03 函数调用
在汇编语言中,函数调用是通过一系列的指令来完成的。以下是一个基本的汇编层面的函数调用过程:
- 将函数的参数传递到寄存器中。通常情况下,函数的参数被存储在栈中,然后被加载到寄存器中。
- 调用函数。在x86体系结构中,函数调用使用CALL指令来实现,该指令会将当前程序计数器(PC)的值(即函数的返回地址)压入栈中,并将程序跳转到被调用函数的入口地址。
- 在被调用函数中,首先保存调用者保存的寄存器的值。为了防止调用者和被调用者之间的寄存器值冲突,被调用函数需要在开始时保存这些寄存器的值。这些寄存器的值在函数结束时需要恢复。
- 在被调用函数中,为局部变量分配空间。函数中的局部变量通常会被存储在栈中。
- 在被调用函数中,执行函数体代码。
- 在被调用函数中,将结果返回给调用者。在x86体系结构中,使用RET指令来实现函数的返回。RET指令会弹出栈中的返回地址,并将程序跳转到该地址。
- 在返回到调用者之前,被调用函数需要恢复调用者保存的寄存器的值。
3.1 函数传参
函数传参是指在函数调用时将实参(也称为实际参数)传递给函数的形参(也称为形式参数)。在C语言中,函数传参通常有以下几种方式:
- 值传递:将实参的值复制一份传递给函数的形参。在函数内部修改形参的值不会影响实参的值。
- 指针传递:将实参的地址传递给函数的形参。在函数内部通过指针访问实参,可以修改实参的值。
- 数组传递:将数组名传递给函数的形参,函数可以通过数组名访问数组元素,也可以通过指针方式访问数组元素。
- 结构体传递:将结构体变量传递给函数的形参,可以通过结构体变量的成员访问结构体的元素。
需要注意的是,函数传参的方式不同,对应的内存开销和性能消耗也不同。在实际编程中,应该根据实际需要选择适当的传参方式,以达到最优的程序性能和内存占用。
3.1.1 寄存器传参
x86-64使用了六个寄存器用于传递参数:
示例代码
此处给出一段示例代码:
1 | #include <stdio.h> |
1 | .LC0: |
我们可以注意到在call printf之前编译器对寄存器中的值进行了一系列操作
我们给出printf函数的原型来探究一下这些操作的意义:
printf函数
1 | printf(const char *format, ...); |
其中,第一个参数是格式控制字符串(format string),用于指定输出格式,第二个参数是可变参数(variable argument),用于传递输出的数据。函数返回值为输出的字符数,如果出现错误,则返回负值。
具体来说,格式控制字符串由普通字符和转换说明符(conversion specifier)组成,转换说明符以百分号(%)开头,用于指定输出数据的类型和格式。例如,%d用于输出十进制整数,%s用于输出字符串,%f用于输出浮点数等等。
可变参数使用省略号(…)来表示,它可以传递任意个数、任意类型的参数。在函数内部,可以使用stdarg.h头文件中定义的宏和函数来访问这些可变参数,常用的有va_start、va_arg和va_end函数。
需要注意的是,printf函数在输出时会根据格式控制字符串的指示将数据转换成字符串输出到标准输出设备(通常是终端或者控制台窗口),因此需要保证输出的数据类型与格式控制字符串中指定的类型匹配,否则可能会出现不可预期的错误或者程序崩溃。
引用内容将在结构体传参中详解
我们可以看到printf函数接收一系列参数,在示例代码中
第一行定义了一个标签.LC0,.string表示将接下来的字符串作为常量存储在内存中,并用标签.LC0标记。
mov edi, OFFSET FLAT:.LC0将eax寄存器的值(即3)移动到esi寄存器中,将.LC0的地址(即字符串”x:%d.y:%d”的地址)移动到edi寄存器中,作为函数的第一个参数
对照上面给出的寄存器与函数参数的对应表,我们注意到:
1 | mov DWORD PTR [rbp-4], 3 //x = 3 |
故在调用printf时可以直接从参数寄存器中取值,提高了运行的效率。
3.1.2 栈传参
当我们使用的参数多于六个的时候,函数传参将会回归最原始的调用方式——栈传参
当一个函数被调用时,它的参数会被压入栈中,然后被函数调用代码弹出并使用。下面是一些常见的栈传参的操作:
- 将参数依次压入栈中:在调用函数之前,将所有的参数按照从右往左的顺序依次压入栈中。例如,当函数调用f(a, b, c)时,参数c会先被压入栈中,接着是b,最后是a。在函数调用过程中,栈指针会指向最后一个参数的位置。
- 传递指针或引用类型的参数:当参数是指针或引用类型时,实际上传递的是指针或引用的地址。在调用函数之前,将指针或引用的地址压入栈中,函数调用代码会根据该地址获取实际的参数值。
- 处理不同类型的参数:在将参数压入栈中之前,需要根据参数的类型进行相应的转换。例如,将浮点型参数转换为IEEE 754标准的二进制格式,并按照指定的字节顺序压入栈中。
示例代码
1 | #include <stdio.h> |
1 | .LC0: |
我们注意到这一段汇编代码的操作:
mov DWORD PTR [rbp-20], 5
mov DWORD PTR [rbp-24], 6
mov DWORD PTR [rbp-28], 7
mov DWORD PTR [rbp-32], 8
mov r8d, DWORD PTR [rbp-20] //第五个参数
mov edi, DWORD PTR [rbp-16]
mov ecx, DWORD PTR [rbp-12]
mov edx, DWORD PTR [rbp-8]
mov eax, DWORD PTR [rbp-4]
sub rsp, 8 //分配8位的栈内存
mov esi, DWORD PTR [rbp-32] //将最后一个参数放入寄存器esi中
push rsi //(esi为rsi的低32位)将rsi入栈
mov esi, DWORD PTR [rbp-28] //重复操作
push rsi
mov esi, DWORD PTR [rbp-24]
push rsi
从源代码我们可以看出printf函数一共接受1(字符串)+8(变量)=9个参数,超过了参数寄存器的个数,多余的参数将按照从右到左的顺序放入栈中,于是就有了入栈的操作。
在x86-64架构中,寄存器是64位的,但栈是32位的。当使用mov指令将一个32位的值从内存加载到寄存器中时,通常使用32位通用寄存器,如eax、ebx、ecx、edx等。在将数据压入栈中时,可以使用任何寄存器,因为它们的值最终都将被推送到栈中。
栈传参和寄存器传参的差别
将栈上的数据放到寄存器中再传参相对于直接取栈上的数据传参可能会更快,因为寄存器是CPU内部的高速存储器,访问速度比内存要快得多。而栈作为内存的一部分,访问速度相对较慢。
在将栈上的数据放到寄存器中再传参的情况下,由于数据已经被预先加载到寄存器中,函数执行时无需再次从内存中读取数据,因此可以节省一定的访问时间和带宽消耗。
3.2 结构体传参
在汇编语言中,结构体传参的实现方式与高级语言有所不同。由于汇编语言是直接操作硬件的语言,它没有变量类型和参数类型的概念,因此需要使用特定的寄存器来传递结构体的成员变量。
以x86架构为例,假设有以下结构体定义:
1 | cCopy codestruct Student { |
则可以使用以下汇编代码来传递结构体:
1 | perlCopy codemov edx, offset student.name ; 将name数组的地址传递给edx寄存器 |
在这段汇编代码中,使用寄存器分别存储结构体的成员变量,然后将这些寄存器的值压入栈中,最后调用函数。在函数中,通过栈来获取结构体的成员变量,然后进行相应的操作。
需要注意的是,汇编语言中没有指针类型和引用类型的概念,因此不能直接传递指向结构体的指针。如果需要传递结构体的地址,可以将结构体的地址存储在寄存器中,然后将寄存器的值压入栈中。在函数中,通过栈来获取结构体的地址,然后进行相应的操作。
3.3 不定参数传参
不定参数的函数是指函数的参数个数不确定,可以接受任意数量的参数。C语言中,标准库函数printf就是一个典型的不定参数的函数。
printf函数的原型定义如下:
1 | cCopy code |
其中,第一个参数format是格式化字符串,用于指定输出的格式;后面的参数用于填充格式化字符串中的占位符。由于参数个数不确定,因此在函数定义中使用了省略号(…)表示可变参数。
在调用printf函数时,可以传递任意数量的参数,但必须满足格式化字符串中占位符的类型和数量要求。例如:
1 | perlCopy code |
在这个例子中,格式化字符串中包含了两个占位符:%s和%d,分别用于输出字符串和整数。函数调用时,传递了两个参数:”Alice”和20。
在函数实现中,可以使用stdarg.h头文件中提供的宏来访问可变参数列表。例如,下面是一个简化版的printf函数实现:
1 | perlCopy code#include <stdarg.h> |
在这个实现中,使用了va_list、va_start、va_arg和va_end等宏来访问可变参数列表。具体来说:
- va_list是一个类型,用于声明可变参数列表的变量;
- va_start宏用于初始化可变参数列表,将指针arg指向第一个可变参数;
- va_arg宏用于获取可变参数列表中的参数,根据指定的类型返回参数的值;
- va_end宏用于结束可变参数列表的访问。
需要注意的是,可变参数的类型和数量必须与格式化字符串中的占位符类型和数量匹配,否则会导致不可预期的结果。因此,在实现不定参数的函数时,必须仔细处理参数的类型和数量。
0x04 内存对齐
C语言编译器中的内存对齐是为了优化内存访问,以提高程序的执行效率。在C语言中,变量的内存对齐是由编译器进行控制的,可以通过指定对齐方式来实现。
C语言中的内存对齐规则有以下几个方面:
- 数据类型的对齐方式:不同的数据类型有不同的对齐方式。例如,char类型的对齐方式是1字节,int类型的对齐方式是4字节,double类型的对齐方式是8字节等。
- 结构体的对齐方式:结构体中的变量通常按照其自身的对齐方式进行对齐,但是结构体本身也需要进行对齐。结构体的对齐方式一般是以最宽基本数据类型的大小为基准进行对齐,例如在32位系统中,结构体中的成员变量按照4字节对齐。
- 指针的对齐方式:指针的对齐方式通常和其所指向的数据类型的对齐方式一致。
C语言编译器中可以通过使用特殊的编译指令来控制内存对齐方式,如#pragma pack(n)指令可以设置对齐方式为n字节,attribute((aligned(n)))指令可以指定变量的对齐方式为n字节。在不同的编译器中,内存对齐方式可能有所不同,因此需要根据具体的编译器来进行设置。
为什么内存对齐能提高运行速度
内存对齐能提高执行效率的原因主要是因为它能减少内存访问的次数。
当内存中的变量未对齐时,访问这些变量会导致额外的访问次数。
例如,如果一个4字节的整数未对齐存储在一个地址为3的位置,那么当CPU访问该变量时,需要先读取地址为3的字节,再读取地址为4、5和6的字节,最后组合这些字节来得到这个整数的值。这样的访问过程需要花费额外的时间和计算资源,从而导致程序执行效率降低。
而当内存中的变量按照对齐规则进行存储时,CPU能够直接访问变量所在的地址,从而减少访问次数,提高程序的执行效率。
此外,内存对齐还能优化缓存的使用。现代计算机通常使用缓存来加速内存访问,缓存通常以块的形式进行管理。当内存中的变量未对齐时,可能会导致多个变量存储在同一个缓存块中,从而导致缓存失效率降低。而当变量按照对齐规则存储时,能够保证每个变量占据整数个缓存块,从而最大化缓存的使用效率,提高程序的执行效率。
综上所述,内存对齐能够减少内存访问次数和优化缓存使用,从而提高程序的执行效率。
结语
其实还差了一个编译器优化的选项,但是笔者还没 深入学习。编译器的很多行为都值得深入思考,这对我们 理解计算机的底层设计有很重大的意义。