不同操作系统编译的异同
操作系统
不同的操作系统 windows linux macos
关于操作系统是这样定义的: 操作系统(英语:Operating System,缩写:OS)是管理计算机硬件与软件资源的系统软件,同时也是计算机系统的内核与基石。操作系统需要处理如管理与配置内存、决定系统资源供需的优先次序、控制输入与输出设备、操作网络与管理文件系统等基本事务。操作系统也提供一个让用户与系统交互的操作界面。
什么是操作系统

- OS 存在的意义即是:提供硬件资源的高效管理
- OS提供cpu、存储功能、外部io的封装管理;并对外提供抽象的硬件服务
- OS之间本质的不同在于内核的不同,在于内核对资源的管理和分配理念不同
从硬件角度讲,计算机硬件所提供的功能其实非常简单:CPU 提供的数学四则运算(包括逻辑运算),内存/硬盘提供的数据存储功能,各类接口提供的与外部世界做交互的 I/O。剩下的硬件,都是为了高效整合这三块资源而存在的。而 OS 本身,就是对这三块资源的统一管理与封装,对应用层的用户提供抽象的硬件服务。
它们的本质不同,在于各自的 OS kernel 的实现的不同。也即是,虽然大家面对的是同样一块 CPU、一块内存、几块硬盘,但对这些硬件资源建立的抽象、引入的逻辑概念却是完全不同的。更进一步,基于各自所建立的硬件逻辑概念,对这些概念的处理、建立的资源分配操作/策略的制定,那就更是不同。如此,在不同的逻辑概念体系下,其对硬件的管理理念和效率自然也会出现不同。而这些,才是 Windows 操作系统和 Linux 操作系统真正的不同。
简评:操作系统的不同,到底是哪里不同 - ll kid的文章 - 知乎https://zhuanlan.zhihu.com/p/35683892
- Windows 内核是闭源的,而 Linux 和 macOS 内核是开源的。这意味着开发者可以查看和修改 Linux 和 macOS 内核的源代码,但无法这样做 Windows 内核。
- Windows 内核是基于微内核设计的,而 Linux 和 macOS 内核是基于单内核设计的。微内核将操作系统分解成小的、独立的部分,以提高系统的稳定性和安全性;单内核则将大部分操作系统功能集中在一个内核中。
- Linux 和 macOS 内核都是基于类 Unix 的设计,而 Windows 内核则不是。这意味着 Linux 和 macOS 内核的命令行工具和文件系统组织方式与 Unix 相似,而 Windows 内核则具有自己独特的命令行工具和文件系统组织方式。
- Windows 内核和 macOS 内核都是封闭的操作系统,而 Linux 内核则广泛应用于开源操作系统,例如 Ubuntu、Debian、Fedora、Red Hat 等。
- Windows 内核和 macOS 内核都是商业操作系统的一部分,而 Linux 内核则可以自由下载和使用,因此在开发和嵌入式系统中广泛应用。
- Windows 内核和 macOS 内核都专注于图形界面的开发,而 Linux 内核则在服务器和嵌入式系统领域得到广泛应用。
宏核和微内核
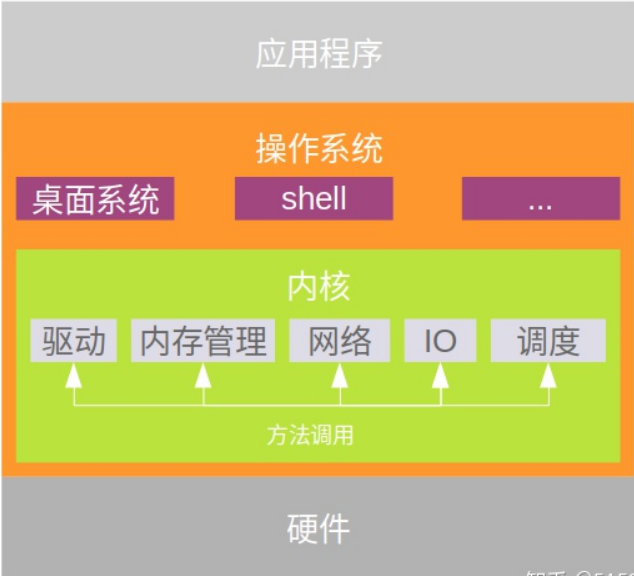
内核管理着操作系统的内存,文件,IO,网络等等,每个功能可以看做一个模块,在宏内核中,这些模块都是集成在一起的,运行在内核进程中,模块之间的交互直接通过方法调用。
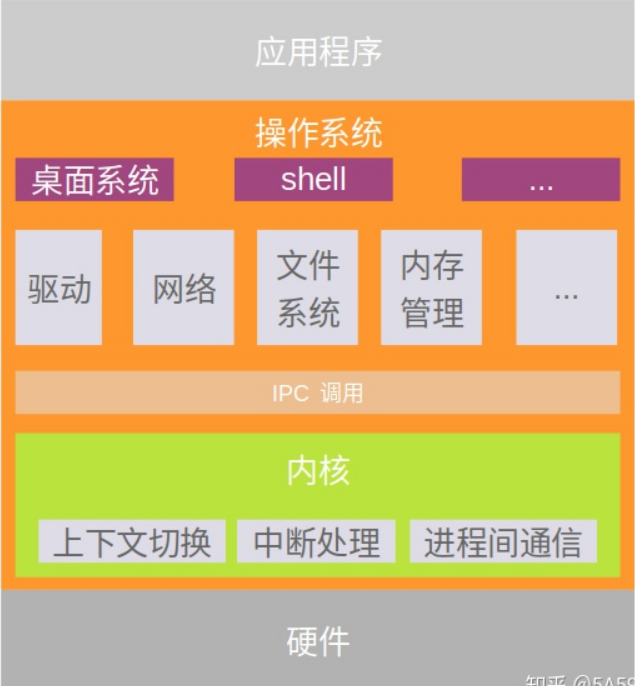
而在微内核中,内核只提供最核心的功能,比如任务调度,内存管理等等,其他模块被移出内核,运行在不同的进程中,这样即使某一个模块出现问题,只要重启这个模块的进程即可,不会影响到其他模块,稳
定性大大增加。
五分钟了解操作系统内核 - ZYLAB的文章 - 知乎 https://zhuanlan.zhihu.com/p/81883894
不同操作系统下的库文件
在实际软件开发中,软件由许多文件组成。不同操作系统下这些组成文件也不一样,本文总结在几种操作系统(Windows、linux、macOS)下软件的库文件,也包含在实际项目开发中,所使用的库。

编译 链接 装载的过程
编译、链接和装载是程序从源代码到可执行文件的过程中必不可少的环节,它们通常被分为以下三个步骤:
1. 编译
编译是将源代码翻译成机器语言的过程。编译器会将源代码转换成中间代码,然后进行优化和转换,生成可执行代码。这个过程通常包括以下步骤:
- 预处理:将代码中的预处理指令(如 #include、#define)进行处理,生成预处理后的代码。
- 编译:将预处理后的代码翻译成汇编语言,生成汇编代码。
- 汇编:将汇编代码翻译成机器语言,生成目标文件。
2. 链接
链接是将目标文件中的符号(如函数名、变量名)与其他目标文件或库文件中的符号进行关联的过程。这个过程通常包括以下步骤:
- 符号解析:将目标文件中的符号与其他目标文件或库文件中的符号进行匹配。
- 重定位:将代码中的地址和数据引用转换成可执行文件中的实际地址和数据。
- 生成可执行文件:将所有目标文件和库文件中的代码和数据合并,生成可执行文件。
3. 装载
装载是将可执行文件加载到内存中并开始执行的过程。这个过程通常包括以下步骤:
- 加载可执行文件:将可执行文件的代码和数据加载到内存中。
- 分配内存空间:为可执行文件分配内存空间,使其可以在内存中运行。
- 解析符号引用:将可执行文件中的符号引用解析成实际的地址。
- 转移控制权:将程序的控制权转移到可执行文件中的入口点。
总的来说,编译、链接和装载是程序从源代码到可执行文件的重要步骤。理解这些步骤的原理和过程,对于开发高质量的软件非常重要。
静态链接库的装载过程
- 将可执行文件和所有的静态库文件读入内存。
- 链接器将所有库文件中的代码和数据复制到可执行文件中,并解析符号引用,以便可以正确地调用静态库中的函数。
- 加载程序的入口点,并开始执行程序。
动态链接库的装载过程
- 将可执行文件读入内存。
- 在可执行文件中找到需要的动态库文件。
- 加载所需的动态库文件,并将其代码和数据映射到进程的地址空间中。
- 解析动态库中的符号引用,以便可以正确地调用其中的函数。
- 加载程序的入口点,并开始执行程序。
需要注意的是,静态链接库在编译时就已经被链接到可执行文件中,因此它们在程序运行时不需要再进行额外的装载。相比之下,动态链接库在程序运行时需要被装载,这可能会稍微增加程序的启动时间。但是,由于多个程序可以共享同一个动态库,因此在一些情况下使用动态链接库可以减少程序的内存占用,并提高系统的效率。
此外,一些操作系统提供了动态链接器(dynamic linker)来处理动态链接库的装载过程。例如,Linux 操作系统中的动态链接器是 ld.so。在程序启动时,动态链接器会在系统的默认路径中查找所需的动态库文件,并将它们装载到程序的内存空间中。如果动态库文件无法找到或加载失败,则程序将无法运行。
不同操作系统下编译链接装载过程的不同
静态链接库
静态链接库是一种包含可重用代码的归档文件,它的代码被编译为可执行文件的一部分。在编译时,链接器将静态库的代码直接复制到可执行文件中,因此它们可以直接在运行时使用,而无需在运行时加载。在不同的操作系统中,静态链接库的格式和装载方式可能有所不同。
Windows
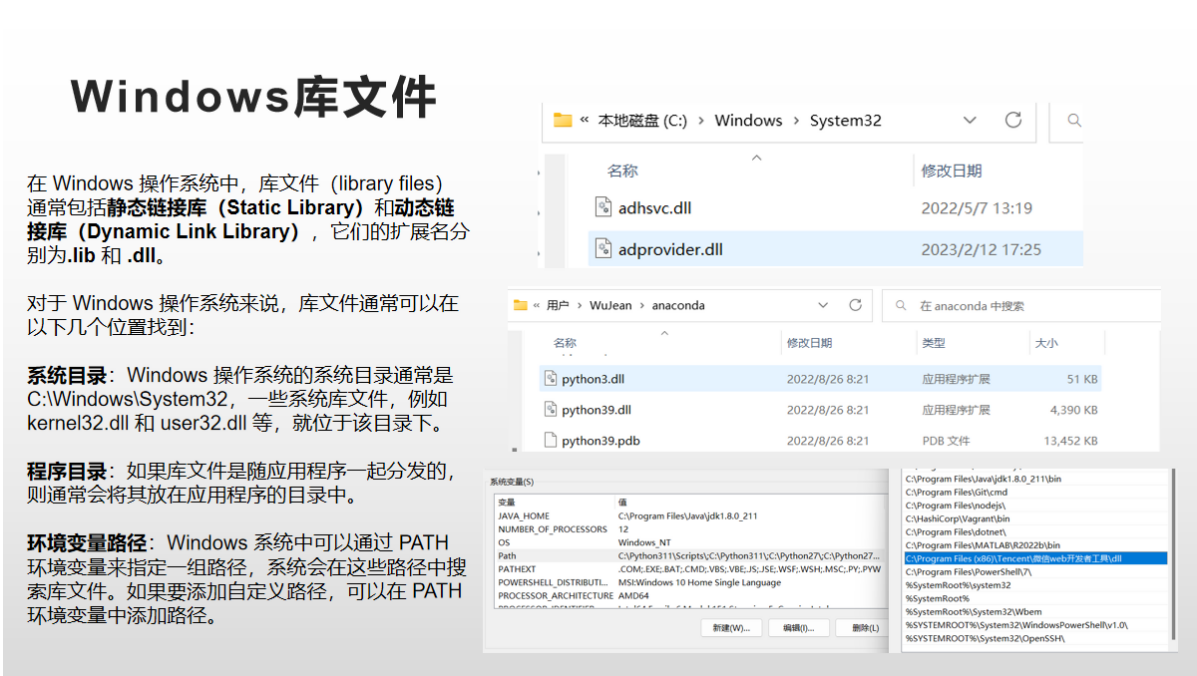
在 Windows 操作系统中,静态链接库的文件扩展名为 .lib,它们包含已编译的二进制代码和与该库相关的符号表。在链接可执行文件时,编译器会将必要的库文件(.lib 文件)与可执行文件链接在一起。当程序运行时,库的代码将被直接复制到可执行文件的内存中。
Linux
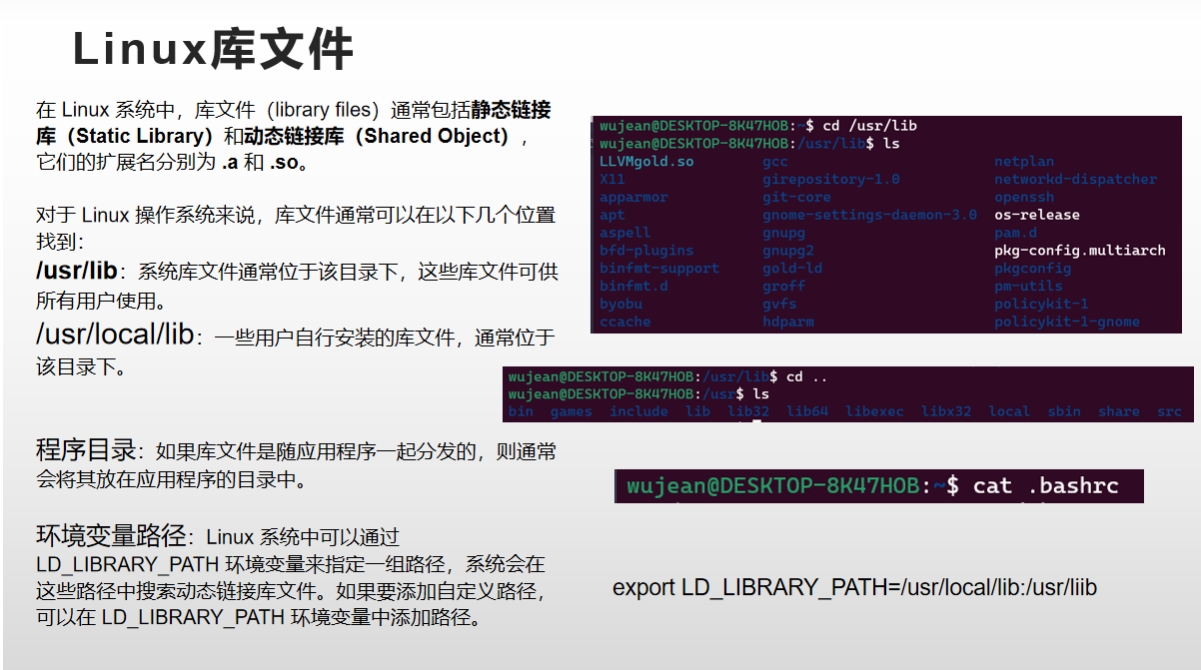
在 Linux 操作系统中,静态链接库的文件扩展名为 .a,它们也包含已编译的二进制代码和与该库相关的符号表。在链接可执行文件时,编译器会将必要的库文件(.a 文件)与可执行文件链接在一起。当程序运行时,库的代码将被直接复制到可执行文件的内存中。
动态链接库
与静态链接库不同,动态链接库的代码在程序运行时才会被装载,因此它们在磁盘上只存储一次,可以供多个程序使用。不同的操作系统可能有不同的动态链接库格式和装载方式。
Windows
在 Windows 操作系统中,动态链接库的文件扩展名为 .dll。当一个程序需要使用某个库时,操作系统会在内存中加载该库,并将该库的函数和数据地址添加到程序的进程地址空间中。多个程序可以同时共享一个 .dll 文件,从而减少了内存的使用。
Linux
在 Linux 操作系统中,动态链接库的文件扩展名为 .so。与 Windows 中的 .dll 文件类似,当一个程序需要使用某个库时,操作系统会在内存中加载该库,并将该库的函数和数据地址添加到程序的进程地址空间中。多个程序也可以同时共享一个 .so 文件。
装载过程
Windows
加载器加载 PE 文件头信息,包括可执行文件入口点 RVA 和各种区段的 RVA 和大小信息。
Linux
加载器加载 ELF 文件头信息,包括可执行文件入口点地址和各个段的虚拟地址和大小信息。
PE和ELF文件头
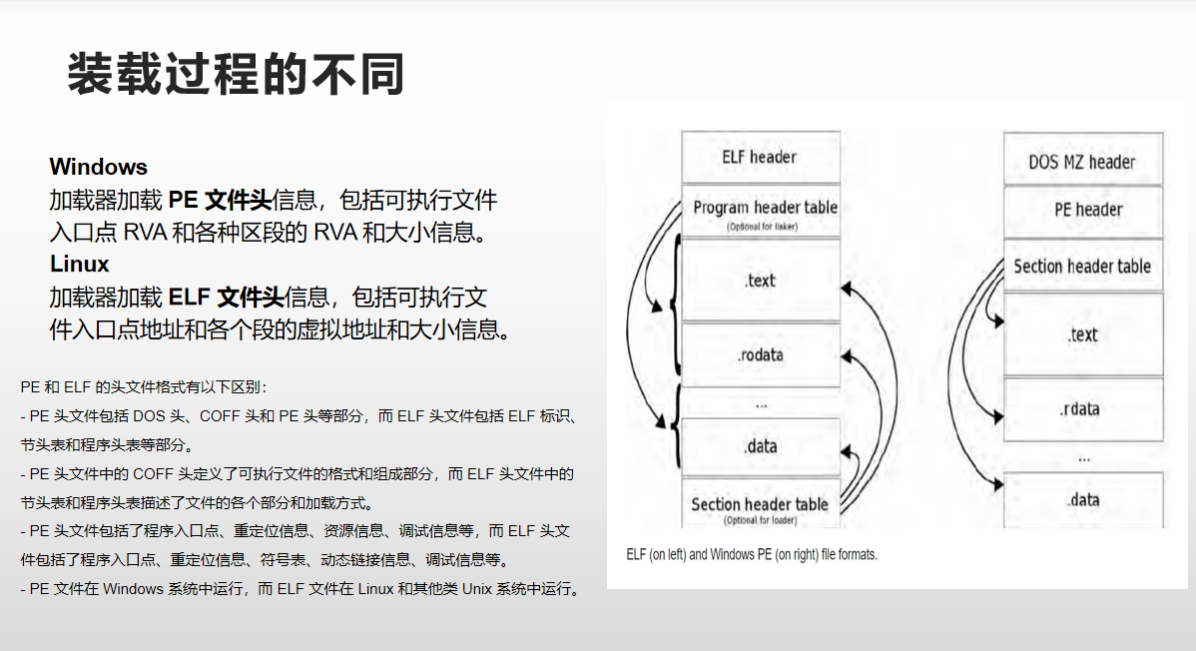
PE(Portable Executable)和 ELF(Executable and Linkable Format)都是可执行文件的格式,但是它们使用了不同的头文件格式。
PE 格式是 Microsoft Windows 系统中可执行文件的标准格式,包括 EXE、DLL、OCX 等。PE 文件的头部信息存储在 PE 头(Portable Executable Header)中,包括 DOS 头、COFF 头、PE 头以及节表等。其中,COFF 头(Common Object File Format)是可移植的目标文件格式,它定义了可执行文件的格式和组成部分。PE 头中还包括了程序入口点、重定位信息、资源信息、调试信息等。
ELF 格式是 Linux 和其他类 Unix 系统中可执行文件的标准格式。ELF 文件的头部信息存储在 ELF 头(Executable and Linkable Format Header)中,包括 ELF 标识、节头表、程序头表等。其中,节头表(Section Header Table)用于描述文件的各个部分,程序头表(Program Header Table)用于描述文件的加载和运行方式。ELF 头中还包括了程序入口点、重定位信息、符号表、动态链接信息、调试信息等。
PE 和 ELF 的头文件格式有以下区别:
- PE 头文件包括 DOS 头、COFF 头和 PE 头等部分,而 ELF 头文件包括 ELF 标识、节头表和程序头表等部分。
- PE 头文件中的 COFF 头定义了可执行文件的格式和组成部分,而 ELF 头文件中的节头表和程序头表描述了文件的各个部分和加载方式。
- PE 头文件包括了程序入口点、重定位信息、资源信息、调试信息等,而 ELF 头文件包括了程序入口点、重定位信息、符号表、动态链接信息、调试信息等。
- PE 文件在 Windows 系统中运行,而 ELF 文件在 Linux 和其他类 Unix 系统中运行。
总的来说,PE 和 ELF 格式的可执行文件都包含了可执行代码、数据、符号表、重定位信息、调试信息等部分,但是它们使用了不同的头文件格式,因此在不同的操作系统和开发环境中需要使用相应的编译器和链接器来生成可执行文件。
gitee源代码地址: https://gitee.com/qq827992983/PE_and_ELF
Windows的可执行文件格式为PE格式,
https://blog.51cto.com/14207158/2570519
Linux的可执行文件格式为ELF格式,
编译器
- 代码风格和语法支持:不同编译器对 C/C++ 语言标准的支持程度可能不同,例如,一些编译器可能支持 C++11 或 C++14 标准,而一些老的编译器可能只支持 C++03 标准。此外,不同编译器还可能有不同的代码风格和编码习惯,如缩进、命名规范、变量声明等。
- 代码优化:编译器会对源代码进行优化,以提高程序的运行效率。不同编译器可能采用不同的优化算法和策略,导致编译后的程序性能差异较大。有些编译器甚至支持特定的优化选项,可以根据应用场景选择合适的优化选项来提高程序性能。
- 代码生成:编译器会将源代码转化为目标代码,并生成可执行文件。不同编译器生成的目标代码可能会有不同的代码质量和大小,影响程序的运行效率和占用空间。
- 依赖库:编译器需要使用系统库和其他依赖库来编译程序。不同编译器可能支持的库和版本不同,使用不同的编译器可能需要重新配置依赖库的路径和版本。
综上所述,不同编译器对程序编译的影响是多方面的,包括代码风格、语法支持、代码优化、代码生成和依赖库等。在选择编译器时,需要根据具体的应用场景和需求进行选择,以获得最优的性能和效果。同时,需要注意编译器的兼容性,避免出现编译错误和兼容性问题。
- 指令集不同:不同的处理器架构使用不同的指令集,例如 x86 架构使用 x86 指令集,ARM 架构使用 ARM 指令集。因此,在编译时生成的指令也会有所不同,这就导致了生成的可执行文件的大小和性能特点不同。
- 对齐方式不同:不同的处理器架构对于数据的对齐方式要求不同。例如,在 x86 架构上,访问未对齐的数据并不会导致错误,但是在 ARM 架构上,访问未对齐的数据可能会导致程序异常终止。因此,在编译时需要注意对数据的对齐方式进行设置。
- 指针大小不同:不同的处理器架构对于指针的大小要求不同。例如,在 x86 架构上,指针大小通常是 4 字节或 8 字节,而在 ARM 架构上,指针大小通常是 4 字节。因此,在编写程序时需要注意指针的大小,以确保程序在不同的处理器架构上都能正常运行。
- 浮点数支持不同:不同的处理器架构对于浮点数的支持方式不同。例如,在 x86 架构上,通常使用 x87 浮点单元来进行浮点数运算,而在 ARM 架构上,通常使用 NEON SIMD 指令来进行浮点数运算。因此,在编译时需要根据目标处理器架构选择适当的浮点数支持方式。
- 寄存器数量不同:不同的处理器架构拥有的寄存器数量不同。例如,在 x86 架构上,有通用寄存器和专用寄存器等多种寄存器,而在 ARM 架构上,有 16 个 32 位通用寄存器和一些专用寄存器。因此,在编写程序时需要注意如何合理利用寄存器,以获得更好的性能。
综上所述,处理器架构对编译的影响很大,不同的处理器架构要求不同的编译方式和编译选项,因此在编写程序时需要根据目标处理器架构进行相应的优化,以获得更好的性能和兼容性。
实例
好的,下面我以一个简单的C语言程序 hello.c 为例,演示在不同的环境下生成可执行文件的过程和结果,以及对比不同环境下生成的可执行文件的大小、性能和兼容性。
首先,这是 hello.c 程序的源代码:
1 | #include <stdio.h> |
然后我们可以在不同的环境下使用不同的编译器和选项生成可执行文件。
在 Linux 环境下生成可执行文件
在 Linux 环境下,我们可以使用 GCC 编译器来编译这个程序。假设我们已经安装了 GCC 编译器,那么我们可以使用以下命令生成可执行文件:
1 | gcc -o hello hello.c |
这个命令会将 hello.c 编译成一个名为 hello 的可执行文件。这个可执行文件的大小是 8.5KB,可以使用以下命令查看:
1 | ls -lh hello |
输出:
1 | -rwxr-xr-x 1 user user 8.5K Feb 23 11:13 hello |
我们也可以使用 GCC 的优化选项来生成更小的可执行文件。例如,使用 -Os 选项可以启用大小优化,减小可执行文件的大小:
1 | gcc -Os -o hello hello.c |
这个命令生成的可执行文件的大小是 8.0KB,稍微小了一些。
可执行文件的性能和兼容性比较
在不同的环境下生成的可执行文件,其性能和兼容性也可能不同。在这里,我们将对不同环境下生成的可执行文件进行性能和兼容性比较。
性能比较
为了比较不同环境下生成的可执行文件的性能,我们可以使用 time 命令来测试程序运行的时间。在 Linux 环境下
在 Linux 环境下,我们可以使用 time 命令来测试程序运行的时间:
1 | time ./hello |
输出:
1 | Hello, World! |
我们可以看到,程序几乎是瞬间运行完毕的,所以在这个简单的示例程序中,性能几乎没有差别。
在 Windows 环境下,我们也可以使用类似的命令来测试程序运行的时间:
1 | .\hello.exe |
输出:
1 | Hello, World! |
由于 Windows 环境下没有内置的 time 命令,我们可以使用第三方工具来测试程序运行的时间。例如,我们可以使用 GNU Win32 的 time 命令来测试程序运行的时间:
1 | time .\hello.exe |
输出:
1 | Hello, World! |
我们可以看到,程序的运行时间非常短,所以性能差别也很小。
兼容性比较
在不同的操作系统和处理器架构下,可执行文件的兼容性也可能不同。为了测试在不同的操作系统上运行可执行文件的情况,我们可以将可执行文件拷贝到另一台计算机上运行。
在 Linux 环境下生成的可执行文件只能在 Linux 系统上运行,而在 Windows 环境下生成的可执行文件只能在 Windows 系统上运行。这是因为不同的操作系统使用的是不同的可执行文件格式,而且操作系统本身提供的系统调用也不同。
另外,不同的处理器架构也可能导致可执行文件的兼容性问题。例如,在 x86 架构的处理器上编译的可执行文件不能在 ARM 架构的处理器上运行,因为它们使用的指令集不同。
因此,在选择编译器和编译选项时,需要考虑目标操作系统和处理器架构,以确保生成的可执行文件具有良好的兼容性。
总的来说,不同的环境下生成的可执行文件的大小、性能和兼容性可能会有所不同,需要根据具体情况进行选择。在实际开发中,通常会根据目标平台的特点选择合适的编译器和编译选项,以确保生成的可执行文件具有最佳的性能和兼容性。