ucore-lab0 and 1
本实验仅仅是记录个人的实验过程,并不带有任何教程性质和可参考性
为了方便在远程访问,本实验将全程在nuc9上编写
实验环境:
- nuc9幽灵峡谷
- esxi8.0 ubuntu22.04
- 必须是desktop版本!一定要!
设置实验环境
直接在github拉取代码文件:
1 | git clone https://github.com/chyyuu/ucore_lab.git |
安装硬件模拟器QEMU
1 | sudo apt-get install qemu-system |
编程方法和通用数据结构
了解一个操作系统的底层构造,最重要也是最基础的就是了解它的编程方法和通用的数据结构。
编程方法
采用了面向对象编程以及方法接口:
1 | // pmm_manager is a physical memory management class. A special pmm manager - XXX_pmm_manager |
将函数封装好,我们需要调用时只需要调用对应的函数指针就行。
通用数据结构
双向链表结构
在uCore内核(从lab2开始)中使用了大量的双向循环链表结构来组织数据,包括空闲内存块列表、内存页链表、进程列表、设备链表、文件系统列表等的数据组织(在[labX/libs/list.h]实现)
uCore的双向链表结构定义为:
1 | struct list_entry { |
需要注意uCore内核的链表节点list_entry没有包含传统的data数据域,,而是在具体的数据结构中包含链表节点。以lab2中的空闲内存块列表为例,空闲块链表的头指针定义(位于lab2/kern/mm/memlayout.h中)为:
1 | /* free_area_t - maintains a doubly linked list to record free (unused) pages */ |
而每一个空闲块链表节点定义(位于lab2/kern/mm/memlayout)为:
1 | /* * |
这样以free_area_t结构的数据为双向循环链表的链表头指针,以Page结构的数据为双向循环链表的链表节点,就可以形成一个完整的双向循环链表。
这种通用的双向循环链表结构避免了为每个特定数据结构类型定义针对这个数据结构的特定链表的麻烦,而可以让所有的特定数据结构共享通用的链表操作函数。
对链表的操作
初始化
list_init(list_entry_t *elm)插入
__list_add(list_entry_t *elm, list_entry_t *prev, list_entry_t *next)删除
list_del(list_entry_t *listelm)访问链表节点所在的宿主数据结构
Linux为此提供了针对数据结构XXX的le2XXX(le, member)的宏,其中le,即list entry的简称,是指向数据结构XXX中list_entry_t成员变量的指针,也就是存储在双向循环链表中的节点地址值, member则是XXX数据类型中包含的链表节点的成员变量。例如,我们要遍历访问空闲块链表中所有节点所在的基于Page数据结构的变量,则可以采用如下编程方式(基于lab2/kern/mm/default_pmm.c):
1
2
3
4
5
6
7//free_area是空闲块管理结构,free_area.free_list是空闲块链表头
free_area_t free_area;
list_entry_t * le = &free_area.free_list; //le是空闲块链表头指针
while((le=list_next(le)) != &free_area.free_list) { //从第一个节点开始遍历
struct Page *p = le2page(le, page_link); //获取节点所在基于Page数据结构的变量
……
}
这部分内容适合二刷,第一次做只需要稍微了解一下就行
Lab 1 系统软件启动过程
lab1中包含一个bootloader和一个OS。这个bootloader可以切换到X86保护模式,能够读磁盘并加载ELF执行文件格式,并显示字符。而这l为了实现lab1的目标,lab1提供了6个基本练习和1个扩展练习,要求完成实验报告。
对实验报告的要求:
- 基于markdown格式来完成,以文本方式为主。
- 填写各个基本练习中要求完成的报告内容
- 完成实验后,请分析ucore_lab中提供的参考答案,并请在实验报告中说明你的实现与参考答案的区别
- 列出你认为本实验中重要的知识点,以及与对应的OS原理中的知识点,并简要说明你对二者的含义,关系,差异等方面的理解(也可能出现实验中的知识点没有对应的原理知识点)
- 列出你认为OS原理中很重要,但在实验中没有对应上的知识点
b1中的OS只是一个可以处理时钟中断和显示字符的幼儿园级别OS。
练习
在github中clone来的代码中没有源代码仓库,找了一圈后发现源代码在master分支中。运行:
1 | git checkout master |
来到主分支,即可查看源代码开始实验。
1 | cd labcodes/lab1/ |
前往lab1的源代码目录。
练习1
题目
列出本实验各练习中对应的OS原理的知识点,并说明本实验中的实现部分如何对应和体现了原理中的基本概念和关键知识点。
在此练习中,大家需要通过静态分析代码来了解:
- 操作系统镜像文件ucore.img是如何一步一步生成的?(需要比较详细地解释Makefile中每一条相关命令和命令参数的含义,以及说明命令导致的结果)
- 一个被系统认为是符合规范的硬盘主引导扇区的特征是什么?
解答1
- ucore
- kernel
- bootblock
ucore
由题目可知我们需要分析ucore.img是如何生成的,我们首先要找到Makefile中有关于ucore生成的部分。
编译用的函数
1 | listf_cc = $(call listf,$(1),$(CTYPE)) |
$(call listf,$(1),$(CTYPE))函数会返回指定目录下的所有符合指定文件类型的文件列表,$(1)和$(CTYPE)是该函数的参数。
$(call add_files,$(1),$(CC),$(CFLAGS) $(3),$(2),$(4))函数用于将指定目录下的源文件编译成目标文件,并添加到编译对象列表中,$(1)、$(CC)、$(CFLAGS)、$(3)、$(2)和$(4)是该函数的参数。
$(call create_target,$(1),$(2),$(3),$(CC),$(CFLAGS))函数用于创建目标文件,并链接所有的目标文件成为可执行文件,$(1)、$(2)、$(3)、$(CC)和$(CFLAGS)是该函数的参数。
我们顺藤摸瓜找到这些编译的参数:
1 | HOSTCC := gcc |
HOSTCC是用于编译主机上的程序的C编译器,这里指定为gcc。
HOSTCFLAGS是用于编译主机上的程序的编译选项,包括-g(产生调试信息)、-Wall(启用警告信息)、-O2(开启优化)等。
CC是用于编译目标程序的C编译器,这里使用了$(GCCPREFIX)gcc的形式,表示使用了一个前缀GCCPREFIX来指定编译器。
CFLAGS是用于编译目标程序的编译选项,包括-fno-builtin(禁用内建函数)、-Wall(启用警告信息)、-ggdb(产生调试信息)、-m32(生成32位代码)等。
$(shell $(CC) -fno-stack-protector -E -x c /dev/null >/dev/null 2>&1 && echo -fno-stack-protector)用于判断编译器是否支持-fno-stack-protector选项,如果支持,则添加该选项。
CTYPE用于指定可以编译的文件类型,包括.c和.S(汇编语言)。
查看Makefile中的内容:
1 | # create ucore.img |
代码中的第一行定义了一个名为UCOREIMG的变量,用于表示ucore.img目标文件的路径。
接下来的代码块是一个规则,用于生成ucore.img文件。该规则有两个依赖项,即kernel和bootblock文件。它执行以下操作:
- 使用dd命令将/dev/zero的内容写入ucore.img文件中,总共写入10000个块,每个块的大小由系统决定。
- 使用dd命令将bootblock文件内容复制到ucore.img文件的开头,覆盖掉前面写入的0。
- 使用dd命令将kernel文件内容追加到ucore.img文件中,从第二个块开始,保留前面写入的0。
最后,代码使用make函数create_target创建一个名为ucore.img的目标文件。该函数还会自动将目标文件添加到要构建的目标列表中。
kernel
1 | # create kernel target |
我们可以看到要生成kernel目标需要: kernel.ld $(KOBJS)等依赖
KOBJS在目录kern中,通过统一的脚本来编译
1 | # ------------------------------------------------------------------- |
- KINCLUDE 变量包含了一系列内核代码路径,这些路径被用作编译时的 include 路径。
- KSRCDIR 变量包含了一系列内核代码路径,这些路径被用来构建 kernel 和 libs 目录的源代码列表。
- KCFLAGS 变量被设置为 KINCLUDE 的每个路径前添加 -I 的结果,这样编译器在编译时就能正确地搜索这些路径。
- $(call add_files_cc,$(call listf_cc,$(KSRCDIR)),kernel,$(KCFLAGS)) 调用了两个函数来构建内核代码的编译列表。
- 最后,KOBJS 变量被设置为 $(call read_packet,kernel libs) 的结果
bootblock
1 | # ------------------------------------------------------------------- |
我们在boot文件夹中找到两个需要生成的文件 bootasm bootmain,并使用默认的编译函数来编译。
解答2
一个被系统认为是符合规范的硬盘主引导扇区(MBR,Master Boot Record)的特征如下:
- 大小为512字节。
- 前446字节包含引导程序,最后两个字节为0x55和0xAA(分别是MBR的标志位)。
- 后64字节分成4个16字节的分区表项,每个分区表项描述了一个分区的起始位置、大小和类型。其中,分区类型标识了分区的文件系统类型,例如0x07表示NTFS文件系统,0x83表示Linux文件系统等。
- MBR必须位于硬盘的第一个扇区,即逻辑块地址(LBA)为0的位置。
这些特征符合了BIOS和操作系统对MBR的规范要求,使得系统可以正确地引导硬盘上的操作系统。
练习2 使用qemu执行并调试lab1中的软件
题目
为了熟悉使用qemu和gdb进行的调试工作,我们进行如下的小练习:
- 从CPU加电后执行的第一条指令开始,单步跟踪BIOS的执行。
- 在初始化位置0x7c00设置实地址断点,测试断点正常。
- 从0x7c00开始跟踪代码运行,将单步跟踪反汇编得到的代码与bootasm.S和 bootblock.asm进行比较。
- 自己找一个bootloader或内核中的代码位置,设置断点并进行测试。
解答1(这条没用,请移步折腾完的那条)
按照提示使用单步跟踪:
- 修改 lab1/tools/gdbinit
1 | set architecture i8086 |
- 在 lab1目录下,执行
1 | make debug |
出现如下报错:
1 | wjd@wjd:~/ucore_lab/labcodes/lab1$ make debug |
/bin/sh: 1: gnome-terminal: not found表示找不到Makefile中设置的默认终端,Gnome Terminal 是 Linux 操作系统下的一种终端仿真器,它是 Gnome 桌面环境的一部分。
我们使用的是非图形化界面,故修改Makefile中的终端类型:
1 | ## TERMINAL :=gnome-terminal |
如果您在运行QEMU命令时遇到“gtk initialization failed”错误消息,这通常是由于您没有在终端中启用X11转发(X11 forwarding)引起的。X11转发是一种将X Window System的GUI应用程序显示在远程计算机上的技术,而QEMU需要X11转发来显示图形界面。
翻来覆去最终在Makefile里面找到了非图形化的编译选项
1 | .PHONY: qemu qemu-nox debug debug-nox |
我们在执行make qemu和make debug时候如果不想使用图形化,只需要在后面加上-nox参数。
实在不想折腾了 换个desktop保平安
因为你ssh连接的终端会被qemu的进程强制一直刷新占用,其实用gdb远程调试也是可以解决的,难度会相对比较大,这边还是建议新手用图形化界面降低难度。
修改tools/gdbinit的内容:
1 | file bin/kerne、 |
首先执行continue开始调试,之后使用next和si语句进行单步调试,最后使用x /2i $pc指令查看当前位置附近的两条汇编代码。
lab1_result的Makefile的debug的gdb多个了c,望周知
解答2
现在我们要尝试使用一下启动内核并远程调试:
此时在lab1目录下:
1 | qemu -S -s -hda ./bin/ucore.img -monitor stdio // 启动qemu运行ucore并开启远程调试服务 |
再在lab1目录下执行gdb:
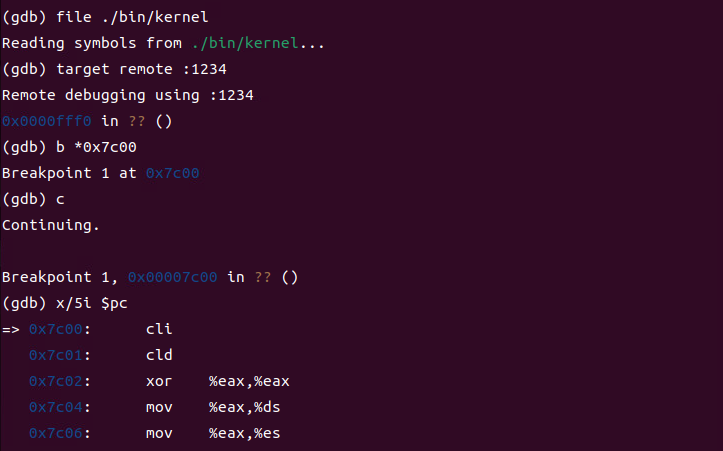
首先使用b *0x7c00指令在该地址处设下断点,然后使用c指令让程序执行至断点位置,最后使用x /5i $pc指令查看当前地址附近的 5 条汇编代码。如下图所示测试断点正常。
解答3
修改lab1下的Makefile如下:

-d和-D是gcc编译器的选项。
- -d选项用于在编译时生成调试信息。这些调试信息包括汇编代码,源代码和符号表等信息,用于在调试代码时使用。
- -D选项用于定义一个宏。该选项后面必须跟一个宏的名称,该名称将被定义为1。在代码中可以使用该宏名称进行条件编译,例如,如果定义了宏,则可以在代码中包含一些特定的功能,否则不包含。
lab1_asm.log是生成的日志文件名称,其中记录了使用-d选项生成的汇编代码信息。
因此,该命令行参数的含义是:使用gcc编译器生成汇编代码并记录到lab1_asm.log文件中。
我们在Makefile的编译内核选项中加入这个参数,将调试得到的汇编代码放入日记文件中便于查看对比。
执行make debug后发现lab1目录下多出了lab1_asm.log文件,将其与bootasm.S和bootblock.asm进行比较后发现长得很像。
解答4
make debug
自己找一个函数打断点分析截图
练习3 分析bootloader进入保护模式的过程
阅读小节“保护模式和分段机制”和lab1/boot/bootasm.S源码
题目
BIOS将通过读取硬盘主引导扇区到内存,并转跳到对应内存中的位置执行bootloader。请分析bootloader是如何完成从实模式进入保护模式的。
提示:需要阅读小节“保护模式和分段机制”和lab1/boot/bootasm.S源码,了解如何从实模式切换到保护模式,需要了解:
- 为何开启A20,以及如何开启A20
- 如何初始化GDT表
- 如何使能和进入保护模式
保护模式和分段机制
Intel 80386只有在进入保护模式后,才能充分发挥其强大的功能,提供更好的保护机制和更大的寻址空间
实模式
在bootloader接手BIOS的工作后,当前的PC系统处于实模式(16位模式)运行状态,在这种状态下软件可访问的物理内存空间不能超过1MB,且无法发挥Intel 80386以上级别的32位CPU的4GB内存管理能力。
实模式将整个物理内存看成分段的区域,程序代码和数据位于不同区域,操作系统和用户程序并没有区别对待,而且每一个指针都是指向实际的物理地址。
通过修改A20地址线可以完成从实模式到保护模式的转换。
保护模式
80386的全部32根地址线有效,可寻址高达4G字节的线性地址空间和物理地址空间,可访问64TB(有2^14个段,每个段最大空间为2^32字节)的逻辑地址空间,可采用分段存储管理机制和分页存储管理机制。
分段存储管理机制
只有在保护模式下才能使用分段存储管理机制。分段机制将内存划分成以起始地址和长度限制这两个二维参数表示的内存块,这些内存块就称之为段(Segment)。
分段机涉及4个关键内容:逻辑地址、段描述符(描述段的属性)、段描述符表(包含多个段描述符的“数组”)、段选择子(段寄存器,用于定位段描述符表中表项的索引)。
- 分段地址转换
- 分段地址转换
段描述符
每个段由如下三个参数进行定义:
- 段基地址(Base Address)
- 段界限(Limit)
- 段属性(Attributes)
解答1
A20线是一根用于控制地址总线的信号线,在早期的x86架构中,由于历史原因和硬件限制,A20线的状态是不稳定的,这会导致地址总线上的某些位不能被正确地设置或读取,从而影响系统的稳定性和可靠性。因此,为了解决这个问题,操作系统需要开启A20线,以确保地址总线的正确性和稳定性。
具体来说,开启A20线可以使得CPU在保护模式下访问超过1MB的内存地址空间,这是因为在实模式下,CPU只能访问1MB以下的内存,而在保护模式下,CPU可以访问超过1MB的内存地址空间,这需要地址总线上的A20线处于稳定状态。
利用键盘控制器(8042芯片):在早期的PC机中,键盘控制器也被用作A20信号线的控制器。通过向键盘控制器发送特定的指令,可以开启或关闭A20线。具体实现方法可以参考Intel手册或者各种开源操作系统的实现代码。
具体操作
分析boot/bootasm.S中开启A20总线的相关代码:
1 | # Enable A20: |
这段代码实现了开启A20地址线的过程,主要包括以下步骤:
- 等待8042芯片的输入缓冲区空闲,以便发送下一条指令。
- 向8042芯片发送0xd1指令,表示要对8042芯片的P2端口进行写操作。
- 再次等待8042芯片的输入缓冲区空闲。
- 向8042芯片的P2端口发送0xdf指令,表示要设置A20地址线的第21位。
- 完成A20地址线的开启。
8042芯片的命令/状态端口是一个8位寄存器,地址为0x64,它包含了8042芯片的状态信息以及接收指令的功能。具体来说,它包含以下位:
- Bit 0(Output Buffer Status,输出缓冲区状态):当该位为0时,表示输出缓冲区中没有数据;当该位为1时,表示输出缓冲区中有数据。
- Bit 1(Input Buffer Status,输入缓冲区状态):当该位为0时,表示输入缓冲区空闲;当该位为1时,表示输入缓冲区正在被使用。
- Bit 2(System Flag,系统标志):该位用于控制系统级别,不在本次讨论范围内。
- Bit 3(Command/Data,指令/数据):当该位为0时,表示将发送的是命令;当该位为1时,表示将发送的是数据。
- Bit 4(Keyboard Locked,键盘锁定):该位用于表示键盘是否被锁定,不在本次讨论范围内。
- Bit 5(Auxiliary Output Buffer Status,辅助输出缓冲区状态):该位用于表示辅助输出缓冲区中是否有数据,不在本次讨论范围内。
- Bit 6(Timeout,超时):当该位为1时,表示接收到的数据已超时。
- Bit 7(Parity Error,奇偶校验错误):当该位为1时,表示接收到的数据存在奇偶校验错误。
在这段代码中,使用了0x64端口的第0位和第1位进行等待和状态检查。
解答2
在x86架构的计算机系统中,GDT(全局描述符表)是一个系统级别的数据结构,用于存储操作系统和应用程序的内存分段信息。GDT表的初始化是操作系统引导过程中的一个重要步骤。
以下是GDT表的初始化步骤:
- 定义一个包含GDT表项的结构体,每个表项描述了一个内存段的起始地址、大小、特权级等信息。
- 为结构体中每个表项设置对应的标识符(段选择符)。
- 将结构体的基地址和大小(表项数目)存储在GDTR(全局描述符表寄存器)中。
- 禁用CPU的保护模式,并使用LGDT(装载全局描述符表寄存器)指令加载GDT表到GDTR寄存器中。
- 重新启用CPU的保护模式,此时GDT表已经初始化完成。
具体操作
1 | # Bootstrap GDT |
这段代码是通过使用汇编语言中的宏定义,定义了三个段描述符并存放在gdt数组中,然后将gdt数组的地址和大小存放在gdtdesc数组中。具体解释如下:
- .p2align 2:这个指令告诉汇编器要将下一个指令的地址对齐到4字节的边界。
- gdt:这是一个标签,定义了一个包含3个段描述符的数组。
- SEG_NULLASM:这个宏定义创建一个值为0的空段描述符。在GDT表中,第一个段描述符必须是空的,因此使用该宏定义将第一个元素设置为NULL段描述符。
- SEG_ASM(STA_X|STA_R, 0x0, 0xffffffff):这个宏定义创建一个代码段描述符,包括代码段基地址为0,段限长为0xffffffff,访问权限设置为可读可执行(STA_X|STA_R)。
- SEG_ASM(STA_W, 0x0, 0xffffffff):这个宏定义创建一个数据段描述符,包括数据段基地址为0,段限长为0xffffffff,访问权限设置为可写(STA_W)。
- gdtdesc:这是一个标签,定义了一个包含两个字(word)和一个双字(long)的数组,其中第一个字表示GDT表的大小,第二个双字表示GDT表的地址。
- .word 0x17:这个字表示GDT表的大小(3 * 8 - 1),其中3表示GDT表中包含3个段描述符,8表示每个段描述符的大小。
- .long gdt:这个双字表示GDT表的地址,指向gdt数组的首地址。
因此,这段代码初始化了一个包含3个段描述符的GDT表,其中第一个段描述符为NULL段描述符,第二个段描述符为可执行的代码段描述符,第三个段描述符为可写的数据段描述符。同时,gdtdesc数组存储了GDT表的大小和地址信息,便于将该GDT表加载到处理器的GDTR寄存器中。
解答3
使能和进入保护模式需要进行以下步骤:
- 初始化GDT表:定义GDT表中的段描述符,包括空段描述符和代码和数据段描述符。这些描述符规定了内存中不同段的起始地址、大小和访问权限等属性。
- 加载GDT表:使用LGDT指令将GDT表的地址和大小(即gdtdesc中的值)加载到GDTR寄存器中。
- 设置CR0寄存器:将CR0寄存器的第0位设置为1,开启保护模式。同时,将CR0寄存器的第16位(即WP位)设置为1,启用写保护模式。
- 进入保护模式:使用汇编指令jmp指令跳转到保护模式代码段的起始地址。此时处理器将处于保护模式,操作系统可以运行在受保护的地址空间内。
具体操作
1 | # Switch from real to protected mode, using a bootstrap GDT |
这段代码使能和进入保护模式的具体步骤如下:
- 加载GDT表:首先通过
lgdt指令加载 GDT 描述符(gdtdesc)中的 GDT 表,告诉处理器要使用哪些段描述符以及每个段描述符的位置和属性。 - 打开保护模式:将
cr0控制寄存器的PE位设置为1,以使能保护模式。 - 切换到保护模式:使用
ljmp指令跳转到protcseg标号所在地址,跳转的目的是为了将处理器切换到 32 位代码段(PROT_MODE_CSEG)。 - 设置段寄存器:切换到保护模式后,需要重新设置段寄存器,以便使用新的段描述符表。首先将数据段选择符(
PROT_MODE_DSEG)存储到ax寄存器中,然后分别将其存储到ds、es、fs、gs、ss寄存器中。 - 设置栈指针:在 16 位实模式下,栈指针一般设置在内存的顶端(0x9ffff),而在保护模式下,需要根据实际情况设置栈指针。这里将栈指针
esp设置为start标号所在地址(0x7c00),栈区间为从0到0x7c00的地址空间。 - 调用 C 函数:设置好栈指针后,调用
bootmain函数,进入内核启动过程。 - 循环等待:如果
bootmain函数返回,说明出现了错误,跳转到spin标号所在地址,进行循环等待。
练习4
题目
通过阅读bootmain.c,了解bootloader如何加载ELF文件。通过分析源代码和通过qemu来运行并调试bootloader&OS,
- bootloader如何读取硬盘扇区的?
- bootloader是如何加载ELF格式的OS?
提示:可阅读“硬盘访问概述”,“ELF执行文件格式概述”这两小节。
解答1
bootloader让CPU进入保护模式后,下一步的工作就是从硬盘上加载并运行OS。考虑到实现的简单性,bootloader的访问硬盘都是LBA模式的PIO(Program IO)方式,即所有的IO操作是通过CPU访问硬盘的IO地址寄存器完成。
磁盘IO地址和对应功能:
第6位:为1=LBA模式;0 = CHS模式 第7位和第5位必须为1
| IO地址 | 功能 |
|---|---|
| 0x1f0 | 读数据,当0x1f7不为忙状态时,可以读。 |
| 0x1f2 | 要读写的扇区数,每次读写前,你需要表明你要读写几个扇区。最小是1个扇区 |
| 0x1f3 | 如果是LBA模式,就是LBA参数的0-7位 |
| 0x1f4 | 如果是LBA模式,就是LBA参数的8-15位 |
| 0x1f5 | 如果是LBA模式,就是LBA参数的16-23位 |
| 0x1f6 | 第0~3位:如果是LBA模式就是24-27位 第4位:为0主盘;为1从盘 |
| 0x1f7 | 状态和命令寄存器。操作时先给命令,再读取,如果不是忙状态就从0x1f0端口读数据 |
当前 硬盘数据是储存到硬盘扇区中,一个扇区大小为512字节。读一个扇区的流程(可参看boot/bootmain.c中的readsect函数实现)大致如下:
- 等待磁盘准备好
- 发出读取扇区的命令
- 等待磁盘准备好
- 把磁盘扇区数据读到指定内存
具体解答
1 | /* waitdisk - wait for disk ready */ |
各地址代表的寄存器意义如下:
- 0x1F0 R,当 0x1F7 不为忙状态时可以读
- 0x1F2 R/W,扇区数寄存器,记录操作的扇区数
- 0x1F3 R/W,扇区号寄存器,记录操作的起始扇区号
- 0x1F4 R/W,柱面号寄存器,记录柱面号的低 8 位
- 0x1F5 R/W,柱面号寄存器,记录柱面号的高 8 位
- 0x1F6 R/W,驱动器/磁头寄存器,记录操作的磁头号、驱动器号和寻道方式,前 4 位代表逻辑扇区号的高 4 位,DRV = 0/1 代表主/从驱动器,LBA = 0/1 代表 CHS/LBA 方式。
- 0x1F7 R,状态寄存器,第 6、7 位分别代表驱动器准备好/驱动器忙
- 0x1F8 W,命令寄存器,0x20 命令代表读取扇区
readseg封装了readsect,通过迭代使其可以读取任意长度的内容,代码如下:
1 | /* * |
这段代码的具体实现:
- 计算读取数据的结束虚拟地址 end_va = va + count;
- 将起始虚拟地址 va 向下取整到扇区边界;
- 计算偏移量对应的扇区号 secno = (offset / SECTSIZE) + 1;
- 使用循环依次读取每个扇区,并将其复制到虚拟地址空间中:
- 循环条件:当 va < end_va 时继续循环;
- 循环迭代操作:将 va 增加一个扇区大小,即 SECTSIZE;将扇区号 secno 增加1;
- 循环体内操作:调用 readsect 函数,将当前扇区的内容读取到虚拟地址 va 对应的内存中。readsect 函数将从磁盘中读取一个扇区的内容,并将其复制到给定的缓冲区中。
解答2
首先看elfhdr、proghdr相关的信息,libs/elf.h代码如下:
1 | #ifndef __LIBS_ELF_H__ |
结合boot/bootmain.c代码分析:
1 | #define SECTSIZE 512 |
当计算机开机时,CPU 会读取 ROM 芯片中的代码,这段代码会在内存中建立起一个最小的操作系统,称为 bootloader。在加载 ELF 格式的操作系统时,bootloader 需要进行以下几个步骤:
- 解析 ELF 文件格式:bootloader 会读取 ELF 文件头部,解析其中的信息,如入口地址、程序头表和节头表等。
- 加载操作系统代码到内存:根据 ELF 文件头部中的入口地址,bootloader 会将操作系统代码从磁盘中加载到内存中的指定地址,一般是加载到内存的高地址空间。
- 设置操作系统环境:在加载操作系统代码之前,bootloader 会设置一些操作系统需要的环境变量,如根文件系统的位置、系统内存大小等等。
- 跳转到操作系统入口地址:当操作系统代码被加载到内存之后,bootloader 会跳转到操作系统的入口地址,将控制权交给操作系统。此时,操作系统便开始执行自己的代码了。
练习5
题目
在lab1中完成kdebug.c中函数print_stackframe的实现,可以通过函数print_stackframe来跟踪函数调用堆栈中记录的返回地址。
在lab1中执行 “make qemu”后,在qemu模拟器中得到类似如下的输出:
1 | …… |
并解释最后一行各个数值的含义。
提示:可阅读小节“函数堆栈”,了解编译器如何建立函数调用关系的。在完成lab1编译后,查看lab1/obj/bootblock.asm,了解bootloader源码与机器码的语句和地址等的对应关系;查看lab1/obj/kernel.asm,了解 ucore OS源码与机器码的语句和地址等的对应关系。
补充材料:
由于显示完整的栈结构需要解析内核文件中的调试符号,较为复杂和繁琐。代码中有一些辅助函数可以使用。例如可以通过调用print_debuginfo函数完成查找对应函数名并打印至屏幕的功能。具体可以参见kdebug.c代码中的注释。
具体实现
前往ucore/labcodes/lab1/kern/debug中找到kdebug.c:
代码已经写好注释,按照逻辑编写即可:
1 | void |
切换栈帧的过程可以分为以下几个步骤:
- 从栈帧中读取调用该函数的函数的基指针(ebp)和返回地址(eip)。
- 将eip设置为即将执行的指令,需要减1才能打印当前函数的信息。
- 将ebp设置为调用该函数的函数的基指针,这样可以访问该函数的参数和局部变量。
代码 ebp = *(uint32_t *)ebp; 的作用是将ebp设置为当前ebp指向的位置,也就是上一个栈帧的基指针的位置。这样,下一次循环就可以访问上一个栈帧的参数和局部变量。
在第一次循环中,当前ebp的值是调用 print_stackframe 函数时的基指针。通过将ebp指向上一个栈帧的基指针的位置,就可以访问调用 print_stackframe 函数时的栈帧中的参数和局部变量。
在lab1目录下执行:
1 | $ make qemu |
1 | Special kernel symbols: |
最后一行的含义是:最初使用堆栈的那一个函数,即bootmain。 bootloader 设置的堆栈从0x7c00开始,使用call bootmain进入bootmain函数。 call 指令压栈,所以bootmain中ebp为0x7bf8。后面的unknow之后的0x00007d71是bootmain函数内调用 OS kernel 入口函数的指令的地址。eip则为0x00007d71的下一条地址,即0x00007d72。后面的args则表示传递给bootmain函数的参数,但是由于bootmain函数不需要任何参数,因此这些打印出来的数值并没有实际意义。(学长写的真的好好)
练习6
题目
请完成编码工作和回答如下问题:
- 中断描述符表(也可简称为保护模式下的中断向量表)中一个表项占多少字节?其中哪几位代表中断处理代码的入口?
- 请编程完善kern/trap/trap.c中对中断向量表进行初始化的函数idt_init。在idt_init函数中,依次对所有中断入口进行初始化。使用mmu.h中的SETGATE宏,填充idt数组内容。每个中断的入口由tools/vectors.c生成,使用trap.c中声明的vectors数组即可。
- 请编程完善trap.c中的中断处理函数trap,在对时钟中断进行处理的部分填写trap函数中处理时钟中断的部分,使操作系统每遇到100次时钟中断后,调用print_ticks子程序,向屏幕上打印一行文字”100 ticks”。
【注意】除了系统调用中断(T_SYSCALL)使用陷阱门描述符且权限为用户态权限以外,其它中断均使用特权级(DPL)为0的中断门描述符,权限为内核态权限;而ucore的应用程序处于特权级3,需要采用`int 0x80`指令操作(这种方式称为软中断,软件中断,Tra中断,在lab5会碰到)来发出系统调用请求,并要能实现从特权级3到特权级0的转换,所以系统调用中断(T_SYSCALL)所对应的中断门描述符中的特权级(DPL)需要设置为3。
解答1
在kern/mm/mmu.h中可以找到表项的结构代码如下:
1 | /* Gate descriptors for interrupts and traps */ |
中断向量表一个表项的大小为16+16+5+3+4+1+2+1+16=8*8=64bit,即8 字节。其中0-15 位和48-63 位分别为偏移量的低 16 位和高 16 位,两者拼接得到段内偏移量,16-31 位gd_ss为段选择器。根据段选择子和段内偏移地址就可以得出中断处理程序的地址。
解答2
实现后的idt_init代码如下:
1 | /* idt_init - initialize IDT to each of the entry points in kern/trap/vectors.S */ |
传入SETGATE的参数:
- 第一个参数 gate 是中断描述符表
- 第二个参数 istrap 用来判断是中断还是 trap
- 第三个参数 sel 的作用是进行段的选择
- 第四个参数 off 表示偏移
- 第五个参数 dpl 表示中断的优先级
这段代码用于初始化中断描述符表(IDT),将每个中断服务例程(ISR)的入口地址设置到IDT中。这些ISR的入口地址定义在kern/trap/vectors.S文件中。代码通过循环遍历IDT中的每个项,使用SETGATE宏将ISR的入口地址、段选择子、特权级等信息设置到对应IDT项中。其中,对于内核代码ISR,特权级设置为内核态权限,而对于用户态ISR,特权级设置为用户态权限。最后,使用lidt指令将IDT的地址加载到中央处理器中。
解答3
由于所有中断最后都是统一在trap_dispatch中进行处理或者分配的,因此不妨考虑在该函数中对应处理时钟中断的部分,对全局变量ticks加 1,并且当计数到达100时,调用print_ticks函数,从而完成每隔一段时间打印100 ticks的功能。
实现后的trap_dispatch代码如下:
1 | /* trap_dispatch - dispatch based on what type of trap occurred */ |
这段代码是一个中断处理函数,根据不同的中断类型进行分发。在函数中使用了一个switch语句,根据中断号判断所发生的中断类型,并执行相应的处理代码。
对于时钟中断IRQ_TIMER,该函数会将全局变量ticks加1,如果当前的ticks是TICK_NUM的倍数,则调用print_ticks()函数打印ticks的值。
对于键盘中断IRQ_KBD和串口中断IRQ_COM1,函数会分别调用cons_getc()函数获取用户输入的字符,并使用cprintf()函数输出到控制台。
对于其他中断类型,如果发生在内核态,则会调用panic()函数输出异常信息并触发内核恐慌。如果发生在用户态,则什么也不做,让用户程序自行处理中断。此外,代码还包含了一个switch语句中的default分支,用于处理未知的中断类型。
总结
操作系统是一个软件,也需要通过某种机制加载并运行它。在这里我们将通过另外一个更加简单的软件-bootloader来完成这些工作。为此,我们需要完成一个能够切换到x86的保护模式并显示字符的bootloader,为启动操作系统ucore做准备。lab1提供了一个非常小的bootloader和ucore OS,整个bootloader执行代码小于512个字节,这样才能放到硬盘的主引导扇区中。通过分析和实现这个bootloader和ucore OS,读者可以了解到:
- 计算机原理
- CPU的编址与寻址: 基于分段机制的内存管理
- CPU的中断机制
- 外设:串口/并口/CGA,时钟,硬盘
- Bootloader软件
- 编译运行bootloader的过程
- 调试bootloader的方法
- PC启动bootloader的过程
- ELF执行文件的格式和加载
- 外设访问:读硬盘,在CGA上显示字符串
- ucore OS软件
- 编译运行ucore OS的过程
- ucore OS的启动过程
- 调试ucore OS的方法
- 函数调用关系:在汇编级了解函数调用栈的结构和处理过程
- 中断管理:与软件相关的中断处理
- 外设管理:时钟
练习概述
练习1:理解通过make生成执行文件的过程
- Makefile
- 了解Makefile的组成结构
- make的细节
- 硬盘主引导扇区
- Makefile
练习2:使用qemu执行并调试lab1中的软件
- 单步跟踪BIOS的执行
- 了解qemu的原理(安卓模拟器-》内核模拟器)
- 了解gdb远程调试及调试命令
- 修改gdbinit
- 修改Makefile中的debug选项
- 添加调试日记(反汇编程序)的内容
- 对比反汇编日志和源代码的区别
- 单步跟踪BIOS的执行
练习3:分析bootloader进入保护模式的过程(阅读源代码 boot/bootasm.S)
- 了解保护模式和分段机制
- 实模式-》保护模式
- 为何开启A20,以及如何开启A20
- 初始化GDT表
- 进入保护模式
- 了解保护模式和分段机制
练习4:分析bootloader加载ELF格式的OS的过程
- 从硬盘上加载并运行OS
- 了解ELF格式(阅读源代码 bootmain.c)
- 加载的操作(阅读源代码 boot/bootmain.c)
- 从硬盘上加载并运行OS
练习5:实现函数调用堆栈跟踪函数(ucore/labcodes/lab1/kern/debug/kdebug.c)
- 了解栈帧的操作
- 了解操作系统启动时的栈帧调度
练习6:完善中断初始化和处理